В статье разберем парсинг сайта poizonshop.ru, который недавно у меня заказали. Стоит оговориться, что клиент мне попался с виду нормальный, а вот люди с которыми он работает – а именно программист, который как оказалось тоже пишет парсеры, поставил мою работу под сомнение и клиента в замешательство. Сегодня разберем нестандартный случай из моей практики. Дадим подсказки, как парсить этот сайт. Нам это уже не нужно, но кому надо – возьмите бесплатно!
Оглавление
Моделирование и оптимизация процессов парсинга
Парсинг ссылок с сайта poizonshop.ru
Извлечение размеров на сайте poizonshop.ru
Извлечение наименований и описаний из карточки товара на poizonshop.ru
Извлечение фотографий с карточки товара на poizonshop.ru
Парсинг цен и наличия с сайта poizonshop.ru
Моделирование и оптимизация процессов парсинга
Каждый программист пишущий парсеры, борется не только со спецификой заказанного сайта, но и с требованиями самого заказчика. Более наглядно изобразим это на математической модели.
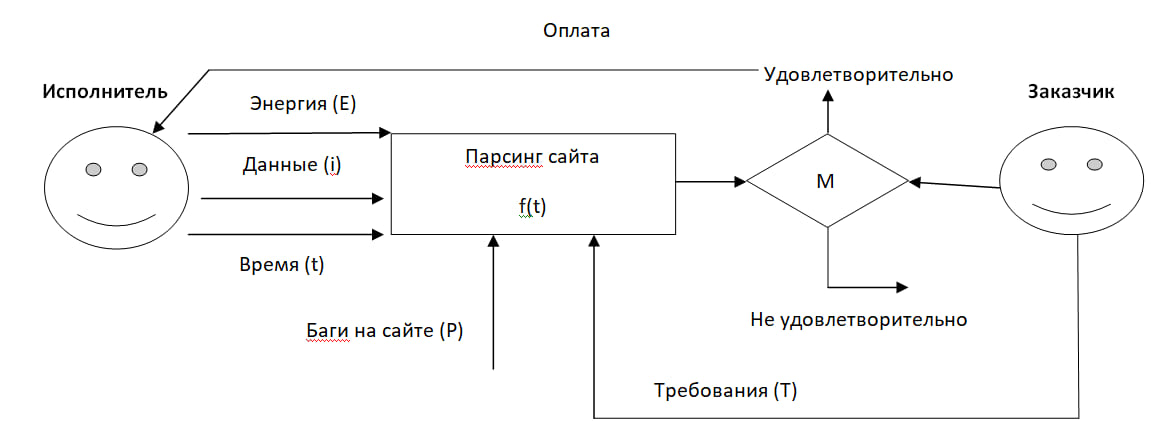
Исполнитель тратит на парсинг свою энергию (внимание + здоровье), свои знания (данные) и время на процесс f(t) – парсинг сайта, который заказал клиент. Клиенту важны сроки выполнения работ. Под буквой М я обозначил – математическое ожидание результата.
Результат либо есть и он один – исполнитель выполнил свою работу и удовлетворил ожидания заказчика, получил за это вознаграждение.
Либо исполнитель потратил свое время, силы и энергию на написание парсера и не получил ничего, потому что не оправдал ожидания клиента.
Под ожиданиями клиента – мы понимаем его требования, которые обозначил я буквой Т на чертеже выше. Не только нужно соблюсти все требования заказчика, но и благополучно извлечь данные из кода. А это не всегда удается, потому что мешают еще баги на сайте (P).
Математическое ожидание положительного результата подчиняется формуле Кристофеля-Дарбу при соблюдении всех требований Т и исправлений всех багов P.
Mtrue = ∫w(t) * f(t)∂t = f(t) * ∑wi = 1
И если заказчик не доволен результатом, то математическое ожидание будет нулевым.
Mfalse = ∫w(t) * f(t)∂t = f(t) * ∑wi = 0
Суммарное количество коэффициентов w кратно суммарному отношению всех исправленных багов в сумме со всеми выполненными правилами - к сумме общему числу багов и правил. После второго знака равно в формуле фигурирует плотность вероятности, где А – суммарное количество всех равновероятностных исходов случайного события, а x – процент заполнения вероятности, j – неполная сумма (jmax ≤ imax).
∑wi = ∑(Tj + Pj)/∑(Ti + Pi) = 1/2log2A = x/100
Двойка в логарифме означает – количество единиц ожидаемых результатов в сумме.
true + false = 2
Изобразить такое можно на схеме.
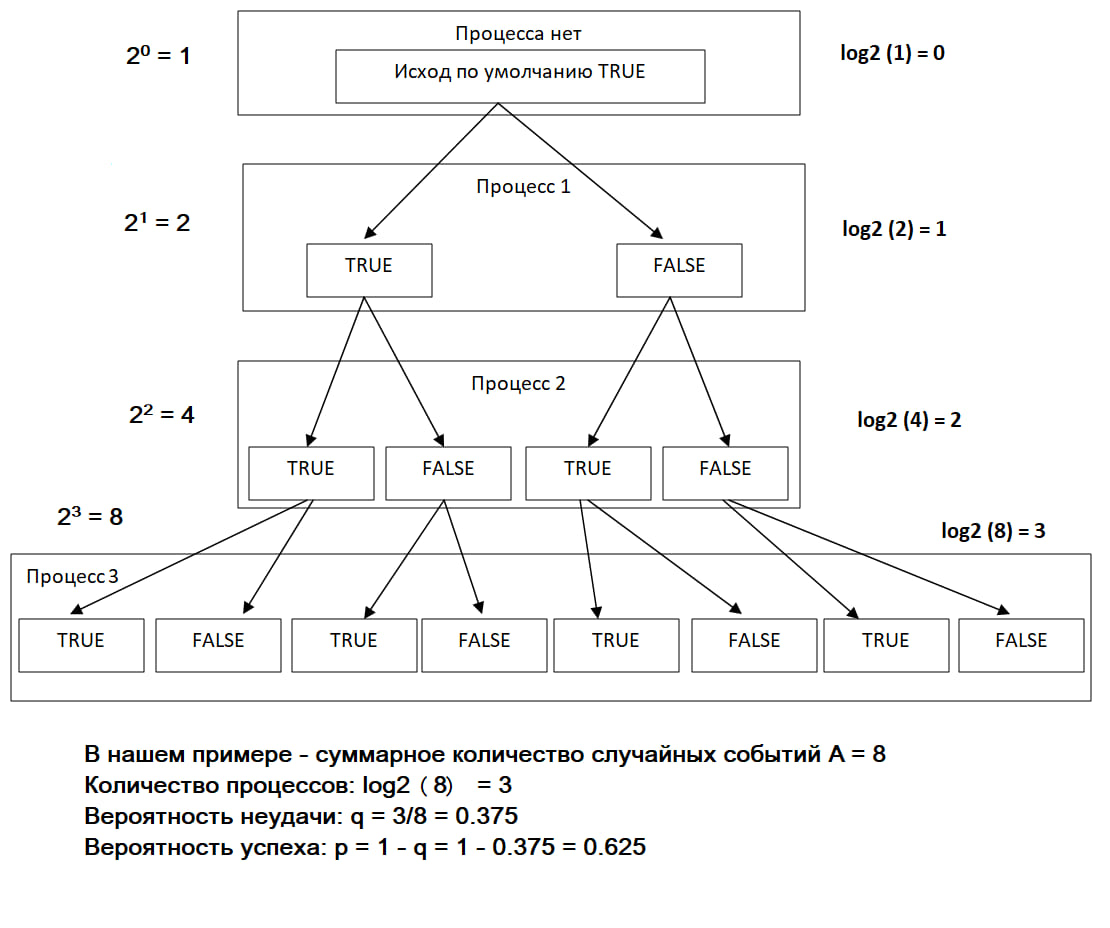
True – результат положительный, False – отрицательный результат. Вероятность того или иного исхода – это 1/2. Но стоит отметить у нас в России такую поговорку: если долго мучиться, то что нибудь получится. Если процессов более двух, то вероятность неудач начинает снижаться. Так как программист тратит время на исправление багов. Он продумывает алгоритмы, которые способны исправить недочеты парсинга, руководствуясь своей логикой.
Так я это к чему. Есть один “умный” программист, который работает с моим клиентом. Заказчик его много лет знает. Программист не знает, как поставить парсер на сайт так, чтобы не положить сам сайт. И считает, что если он не знает, как это сделать, то никто либо другой не в курсе этого.
Я выполнил работу, а он наговорил клиенту всякой ерунды. Заказчик не оплатил заказ, а я остался у разбитого корыта. Погоревав немного, собрался с мыслями и решил написать эту статью.
По логике вещей, если у этого программиста не получается ничего, то значит не получится и у меня спарсить сайт. И конечно клиент решает, что я его кинул.
Давайте попробуем разобраться в парсинге этого сайта, который как он говорит – надо парсить несколько месяцев.
Парсинг ссылок с сайта poizonshop.ru
Для кого-то я раскрою секрет, а для кого-то нет – но есть два способа спарсить ссылки.
Первый способ легкий, но не надежный – через парсинг sitemap.xml. То есть через карту сайта извлечь все ссылки между тегом <url></url>. Если карта редко обновляется, то парсинг будет не полный. Но если CMS обновляет сама карту сайта при создании новой карточки, то очень даже может быть.
<url>https://poizonshop.ru/product/nike-vapormax-7</url>
Второй способ надежный – обойти парсером весь каталог с категориями товаров и извлечь все ссылки категорий, а затем и сами карточки. Пример: одежда, кроссовки, обувь, аксессуары. Этот метод всегда считался эффективным, но только не в этом случае. Как и показал ранее программист на видео, обойти можно только первые 500 страниц категории – а дальше облом.
Именно на этом сайте эффективным оказался первый способ. Ниже я дам ссылку, где скачать sitemap.xml и то, что уже скачено.
| Ссылка на карту сайта карточек товаров PoizonShop: | Перейти |
| База готовых скаченных url-адресов: | Скачать |
Судя по sitemap.xml там оказывается не миллион ссылок, а 124360 штук. А получилось так потому, что я скачал канонические ссылки. Остальные ссылки генерируется через JavaScript GET-параметром “sku” и являются неестественными ссылками.
https://poizonshop.ru/product/asics-dan-gable-evo-3-5624049?sku=628384064
Такие ссылки в поисковых системах Yandex и Google не ранжируются. Со страницы с get-параметром sku=628384064 рекомендуется сделать перелинковку на каноническую страницу без этого параметра.
<link rel = “canonical” href = “https://poizonshop.ru/product/asics-dan-gable-evo-3-5624049”>
Каждый GET-параметр sku имеет свой числовой идентификатор, благодаря которому генерируется страница с одним и тем же товаром, но разным размером. Таких размером на странице много, поэтому 124360 ссылок превращаются в миллион на сайте.
Я же парсил только канонические ссылки. Информацию обо всех размерах товара можно достать из одной канонической страницы.
Извлечение размеров на сайте poizonshop.ru
После парсинга ссылки карточки товара, ее необходимо сохранить и важно сделать вот такую автозамену в файле до сохранения.
str_replace(‘</’, PHP_EOL . ‘</’, $parsing_url);
Чтобы извлечь размеры изделия, прежде всего, сделайте проверку на наличие в спарсенной карточке таких двух кусков HTML-кода, проверяя их в цикле FOR, и между ними поставить логический оператор ИЛИ (||).
<a class="product-size_item__FGXTN" href="'
<a class="product-size_item__FGXTN product-size_active__bWp05" href="'
Если эти строчки встречаются в коде карточки товара, то там или один размер, или несколько. Если их нет, то размеров там не будет – в этом случае игнорим весь этот кусок кода. В том случае, когда эта строчка обнаруживается – то рекомендуется извлечь определенный кусок кода из такой конструкции.
$size = explode(‘<div class="product-size_list__6H2Z7">’, $parsing);
$size_fin = explode(‘</div>’, $size[1]);
На выходе вы получите в переменной $size_fin[0] кусок кода, который потом нужно разбить на переносы строк.
$size_len = explode(PHP_EOL, $size_fin[0]);
Через цикл FOR или FOREACH рекомендуется прогнать все эти строчки на поиск определенных подстрок. Если товара нет в наличии, то применяем внутри цикла такой прием:
if(strstr($size_len[$i], ‘<a class="product-size_item__FGXTN’)) {
$size_plod = explode(‘<a class="product-size_item__FGXTN product-size_unavailable__Iqn0_" href="’, $size_len[$i]);
$size_plod2 = explode(‘”>’, $size_plod[1]);
fputs($database_size, $size_plod2[1]);
}
Обратите особое внимание, что в базу данных Вам нужно записать значение $size_plod2[1], так как в этом элементе массива находится извлеченный размер из карточки товара.
Если есть в наличии, тогда в том же цикле ниже пишем это условие.
if(strstr($size_len[$i], ‘<a class="product-size_item__FGXTN’)) {
$size_plod = explode(‘<a class="product-size_item__FGXTN" href="’, $size_len[$i]);
$size_plod2 = explode(‘”>’, $size_plod[1]);
fputs($database_size, $size_plod2[1]);
}
Если Вы цены собираетесь извлекать, то очень важно тогда извлечь информацию о наличии товара. Если товар есть в наличии, то придется парсить еще и цену. Если нет – то можно ничего не парсить, а тупо в базу данных забить нули.
Если Вы собрались парсить этот сайт, то моя рекомендация будет пока с ценами не торопиться. С ними разберемся после того, когда я расскажу о правильном добавлении парсера на сайт. Так, чтобы парсер не перегружал сервер, работая в комбинаторике с сайтом.
То есть я рекомендую сначала спарсить контент и наделать карточек в цикле, затем подгрузить все данные в карточки товаров и в HTML-шаблон каждой карточки внедрить парсер цен и наличия.
Извлечение фотографий с карточки товара на poizonshop.ru
Тут все очень просто. Из карточки Вам нужно извлечь такой кусок кода из нулевого элемента массива $img_fin[0].
$img = explode(‘</header><div class="page_product_page__mlouT">’, $parsing_url);
$img_fin = explode</div><div class="product-images_indicators__9cvv1">’, $img[1]);
Затем разбить его на переносы строк.
$img_len = explode(PHP_EOL, $img_fin[0]);
А в конце найти по подстроке тег <img> и извлечь между кавычками в атрибуте src значение ссылки, сохранить в базу данных значение нулевой переменной массива $img_exp_fin[0].
for($j = 0; $j < count($img_len); ++$j) {
if(strstr($img_len[$j], ‘<img src’)) {
$img_exp = explode(‘<img src=”’, $img_len[$j]);
$img_exp_fin = explode(‘”’, $img_exp[1]);
fputs($database_img, $img_exp_fin[0]);
}
}
Переменная $img_exp_fin[0] записывается в базу данных, как конечное значение - ссылка на фотографию.
Извлечение наименований и описаний из карточки товара на poizonshop.ru
Наименование можно извлечь из тега <h1>, прибавив вконце размер из переменной $size_plod2[1], которая была описана выше – если есть.
$h1 = explode(‘<h1>’, $parsing_url);
$h1_fin = explode(PHP_EOL, $h1[1]);
if($size_plod2[1] != null) {
fputs($database_h1, str_replace($h1_fin[0], $h1_fin[0].’, размер ’.$size_plod2[1]));
} else {
fputs($database_h1, $h1_fin[0]);
}
А вот description или описание – извлекается через мета-тег <meta>.
$desc = explode(‘<meta name=”description” content=”’, $pasing_url);
$desc_fin = explode(‘”’, $desc[1]);
fputs($database_description, desc_fin[0]);
При желании, можно заменить их название магазина на ваше.
str_replace(‘Poizon Shop’, ‘Ваш Магазин’, $desc_fin[0]);
Парсинг цен и наличия с сайта poizonshop.ru
Для начала Вам нужно создать карточки товаров и в шаблон каждой карточки подтянуть парсер и каждый со своей ссылкой. Парсить он будет только одну карточку, принадлежащей только текущему товару. Пример ниже.
parsing(‘https://poizonshop.ru/product/asics-dan-gable-evo-3-5624049’);
Парсинг цены будет осуществляться только после того, как пользователь будет заходить на страницу. Пользователь зашел, активировал скрипт. Во время загрузки страницы, подтягивается цена с сайта poizonshop.ru и парсер отключается. Нагрузки это практически никакой не создает на сервер.
Если размеров у товара на карточке много, то вам нужно из куска кода $cens_len[0] извлекать данные ($price_fin[0] – обычная доставка, $oldprice_fin[0] – экспресс-доставка).
$cens = explode(‘\"page_product_page__mlouT\"’, $parsing_url);
$cens_fin = explode(‘</script>’, $cens[1]);
$cens_len = explode(‘skuId\’, $cens_fin[0]);
for($k = 0; $k < count($cens_len); ++$k) {
if(strstr($cens_len[$k], ‘\"primary\":\"[РАЗМЕР]’)) {
$price = explode(‘"price\":’, $cens_len[$k]);
$price_fin = explode(‘,’, $price[$k]);
$oldprice = explode(‘"priceWithExpress\":’, $cens_len[$k]);
$oldprice_fin = explode(‘,’, $oldprice[$k]);
echo $price_fin[0];
echo $oldprice_fin[0]; }}
Если всего лишь один или не одного размера в карточке, то немного проще.
$price = explode(‘<span class="product-delivery_price__T15W0"><span>’, $parsing_url);
$price_fin = (‘<!-- -->’, $cens[1]);
$oldprice = explode(‘<span class="product-delivery_price__T15W0"><span>’, $price_fin[1]);
$oldprice_fin = (‘<!-- -->’, $oldprice[1]);
echo $price_fin[0];
echo $oldprice[0];
Можно тупо проигнорировать все эти решения, если товар один и он не в наличии, приравняв сразу все цены к нулю.
echo 0;
echo 0;
Если цена отличная от нуля, то есть наличие. Если нет, то не в наличии.
Проблемы с размерами товаров на сайте poizonshop.ru
Когда будете парсить этот сайт, будьте готовы к багам на нем. Частый баг – дублирование размеров в одном товаре. Например, Вам может попасться товар с несколькими одинаковыми размерами M.
M M M M M
Или повторяющиеся размеры через один-два:
M XL XXL M XL XXL M XL XXL
В этом случае рекомендую после скачивания кода карточек извлечь в отдельный файл все размеры в столбик построчно из каждой карточки и сократить дубли. Я использовал разделитель между размерами – вертикальная черта.
40|41|42|43
M|M|M|M
XL|XXL|XXXL|XL|XXL|XXXL
Далее обходил каждую строчку, и с помощью функции array_unique убирал дубли и перезаписывал без дубля.
40|41|42|43
M|
XL|XXL|XXXL|
Алгоритм примерно такой на PHP, где в db_size.txt были заранее закачены размеры в строку с разделителем |. Каждая строка в файле – это номер url-адреса карточки товара.
$db_size = explode(PHP_EOL, file_get_contents(‘db_size.txt’));
$db_size_unique = fopen(‘db_size.txt’, ‘w’);
for($i = 0; $i < count($db_size); ++$i) {
$unique_size = array_unique(explode(‘|’, $db_size[$i]));
for($j = 0; $j < count($unique_size); ++$j) {
fputs($db_size_unique, $unique_size[$j].’|’);
}
fputs($db_size_unique, PHP_EOL);
}
fclose($db_size_unique);
Таким образом, файл с размерами переписывается, и убираются дубли размеров. Извлечение информации из скаченного html-файла карточки товара прекращается после того, как будет проверен последний размер из файла db_size.txt. Думающий программист поймет, о чем я говорю.
Битые ссылки во время парсинга
Будьте готовы к сюрпризу, когда во время самого парсинга html-кода извлечется битая ссылка. Ссылка считается битой, если на самом сайте она ведет к 404 ошибке или во время парсинга у Вас начались проблемы с интернетом. Во втором случае можно просто перепарсить карточку. В первом же - проигнорировать, когда из скаченного кода будете извлекать нужную Вам информацию. Если вес файла не превышает 60 кБ, то можно ее пропустить
if(filesize($database_url[$i]) >= 60000) {//извлекаем информацию} else {//игнорим}
Если же у вас проблемы с интернетом были, то вес карточки не будет превышать 1 кб. Просто найдите карточки, которые не скачались и перепарсите их.