В статье расскажем, как составить смету по парсингу сайтов. Мы разработали математический аппарат, позволяющий подсчитать цену. Разберем пример с обходом категорий на сайте bidexpert и сбор информации в xml-фид. А также выложим xml-файл со скаченной информацией.

Математическая модель для расчета KPI по парсингу
Стоимость парсинга сайта строится из суммарных показателей эффективности KPI, умноженных на курс в евро, который тянется с сайта ЦБ РФ. У нас есть фреймворк с набором PHP-функций, который подходят для многих сайтов. Программист выбирает из него нужные функции и строит парсер.
Благодаря этим функциям экономится огромное количество времени. Не затрачиваются усилия для написания большого количества строк кода. Каждая функция – это паттерн, позволяющий быстро и оперативно решить ту или иную задачу.
Для расчета KPI какой-то одной определенной задачи мы применяем модель Ситуация / Решение / Результат. Здесь нужно ответить на следующие вопросы:
- Что нужно сделать, чтобы достичь цели?
- Что может помешать добиться цели?
- Как это сделать?
- Какие исходные данные нужны?
- Как обойти то, что мешает добиться цели?
- Каков результат?
Первый вопрос задает цель задачи – например: скачивание html-кода всех подстраниц категории товаров; парсинг url-адресов карточек товаров; скачивание html-кода карточек товаров; сбор характеристик; сбор значений характеристик и другое.
Второй вопрос – что может помешать добиться цели? Ну, тут помешать могут несколько факторов: контент на страницу тянется из JSON и парсер не может скачать данные; защита от DDOS-атак; капча; редирект и многое другое. В данном случае делается тестовое скачивание страницы и если код успешно качается со всеми данными, то никакой защиты на сайте стоять не будет.
Третий вопрос – это использование или разработка паттернов. Как сделать так, чтобы добиться результата из первого вопроса? А для этого
нужны исходные данные, которые являются ответом на четвертый вопрос. И они в нашей математической модели помечаются,
как En – количество входящих данных для выполнения поставленной цели. Ex – это количество исходящих данных, в
большинстве случаев равна 1. Но существуют и частные случаи, когда этот показатель больше единицы. Коэффициент эффективности потока
данных оценивается по формуле ниже для простых php-функций.
E = En/(En + Ex)
В таких языках программирования, как C, Visual C++, Java, Pascal и другие – существует такое понятие, как функция-процедура. Эта функция, которая не принимает в себя никаких значений и ничего не возвращает. Используют тип данных void и называются подпрограммами.
void method() {cout << "Hello World!" << endl;}
method();
Похожие функции есть и в PHP. Процедуры не принимают в себя значений, а также не возвращают ничего командой return. Подпрограмму можно применить в любом участке кода парсера, и она не требуют никаких входных данных. Тем не менее, процедура полезна тем, что не нужно тратить время на ввод данных, а на выходе получаем хороший результат. Для процедур этот показатель равен единице.
E = 1
Когда определились с входными данными, вернемся к третьему вопросу – как выполнить задачу так, чтобы добиться поставленной цели? Возьмем, к примеру, цель – парсинг подстраниц категории. Составим модель.
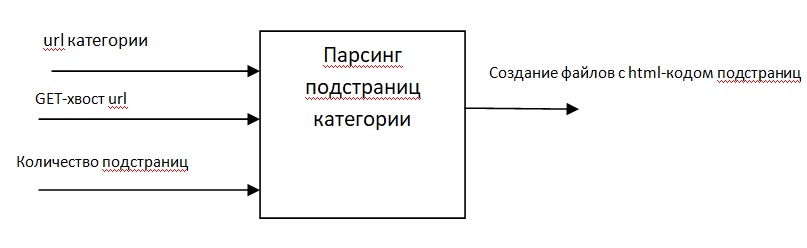
Выполнение данной функции приведет нас на один шаг к достижению главной цели – парсинг всей категории товаров. Количество входных данных En = 3, а на выходе получаем один результат Ex = 1 – создание файлов с html-кодом скаченных подстраниц. По расчету должен получиться следующий результат:
E = 3/(3 + 1) = 3/4 = 0.75
В данном примере, в функцию парсинга добавляется три значения: URL категории, GET-запрос в хвосте URL-адреса каждой подстраницы и количество подстраниц.
function parser($url, $get, $page_count) {
//код функции
return РЕЗУЛЬТАТ;
}
Ниже покажем обрабатываемые запросы этой функцией.
https://site.ru/category?page=1
https://site.ru/category?page=2
https://site.ru/category?page=3
...
https://site.ru/category?page=N
Откуда, https://site.ru/category - это ссылка на категорию, ?page= - get-параметр, ведущий на подстраницы сайта, а числами от 1 до N – количество подстраниц.
Кроме входных и выходных данных следует определить, сколько задач решает функция – обозначим, как Z. Далее определим, сколько всего исходов событий вероятно.
A = 2S
Принимаем весовую функцию, которую будем дифференцировать для получения полиномов Лежандра.
y(t) = -t2 + At
Полиномы Лежандра принимают следующие значения:
T0(t) = 1
T1(t) = 1/1! * ∂/∂t (-t2 + At) = -2t + A
T2(t) = 1/2! * ∂/∂t ∂/∂t (-t2 + At) = 1/2 * ∂/∂t (-2t + A) = 1/2 * (-2) = -1
T3(t) = 1/3! * ∂/∂t ∂/∂t ∂/∂t (-t2 + At) = 1/6 * ∂/∂t ∂/∂t (-2t + A) = 1/6 * ∂/∂t (-2) = 0
...
Tn(t) = 0
Суммарный полином Лежандра будет равен полиному с индексом 1. За t принимается количество действий Z.
∑T = T1(t) = -2t + A = -2Z + A
Теперь найдем функционал, проинтегрировав весовую функцию от 0 до Z.
F(t) = ∫(-t2 + At) ∂t = Z2 * (-Z/3 + 2Z/2)
Плотность весовой функции рассчитывается по формуле ниже.
P = Z * F(t)/A
Рейтинг задачи – это отношение плотности весовой функции к суммарному полиному Лежандра.
R = P/∑T
Когда мы знаем исходные данные в примере, определим количество задач Z:
- Создание папки, куда будут записываться файлы
- Парсинг подстраниц категорий в цикле for.
- Запись каждой спарсенной страницы в файл в созданную папку.
Всего задач Z = 3. Значит всего исходов получится A = 23 = 8. Суммарный полином Лежандра равен ∑T(t) = -2 * 3 + 8 = 2. Функционал F(t) = 32 * (-3/2 + 8/2) = 9 * (-3/2 + 4) = 22.5. Плотность весовой функции будет равна P = 3/8 * 22.5 = 8.4375. Рейтинг будет равен R = 8.4375/2 = 4.21875.
Для решения пятого вопроса, а именно, как обойти то, что мешает добиться цели – есть такой ответ: найти уязвимости на сайте и разработать методы обхода. Так, например, для сайта “Все Инструменты ру ” был придуман метод обхода капчи, который я обозвал – зеркальный парсинг. На этом сайте не позаботились закрыть зеркала в robots.txt и я нашел уязвимость. Кроме того, они туда поставили защиту от досс-атак. В обход я ничего умнее не придумал, кроме как после каждой скаченной страницы парсером поставить время засыпания парсера на 15-20 секунд.
sleep(rand(15, 20));
Без этого способа, скачивались бы страницы по 16 кб и мы бы там ничего кроме JavaScript не увидели.
На шестой вопрос отвечаем после того, как уже выполним задачу. Результат либо удовлетворительный, либо нет. KPI задачи определяется суммой двух слагаемых - рейтинга R и показателя E.
KPI = R + E
Например, для нашего примера: KPI = 4.21875 + 0.75 = 4.96875. Стоимость задачи оценивается в рублях и зависит от курса евро по ЦБ РФ (параметр е).
Ц = KPI * e
Пусть курс евро на 05.06.2024 составляет е = 96.56 руб. Тогда цена в нашем примере будет равна Ц = 4.96875 * 96.56 = 479.78 руб.
Когда цель, которую поставил заказчик парсинга, достигнута – рассчитывается суммарный KPI всех задач в смете и умножается на курс евро. Таким образом, получается полная сумма за парсинг.
Пример расчета цены за парсинг.
Приведем пример расчета сметы парсинга офферов категории “недвижимость” с сайта https://bidexpert.ru/ , основанного на реальных событиях. Слева в колонке будет задача, которая выполняется в процессе достижения цели, а справа – KPI задачи и её себестоимость. Условный курс евро возьмем е = 96.56 руб на 05.06.2024.
| Задача | KPI/Цена |
| Парсинг кода всех подстраниц категории “Недвижимость” | 1.81/174.78 |
| Извлечение ссылок на офферы | 1.3/125.53 |
| Парсинг кода офферов | 1.97/190.22 |
| Извлечение значения тегов META NAME DESCRIPTION из кода офферов | 1.1/106.21 |
| Извлечение дат из кода офферов (публикация, начало и конец приема заявок, начало торгов) | 1.38/133.25 |
| Извлечение технических характеристик из кода офферов | 1.38/133.25 |
| Извлечение значений технических характеристик из кода офферов | 1.38/133.25 |
| Извлечение ссылок на фотографии из кода офферов | 1.38/133.25 |
| Объединение извлеченных данных в xml-файл | 1.2/115.87 |
| Чистка КЭШа парсера | 0.503/48.57 |
| Общая оценка достижения цели | 13.403/1294.19 |
За такой парсинг можно предъявить заказчику 1294.19 рублей. Так как этот парсер я писал для своих личных целей, мне не потребовалось извлекать из кода TITLE, H1, ALT и другие мета-данные. Они там слишком криво написаны и мне пришлось генерировать их из скаченных характеристик. Ниже в таблицу выложу саму извлеченную базу.
| Суммарный KPI парсинга | 13.403 |
| Условный курс евро по ЦБ РФ, руб | 96.56 |
| Условная себестоимость, руб | 1294.19 |
| XML-база офферов | Скачать |
Заключение
Благодаря нашему математическому аппарату, а также фреймворку с набором функций – мы можем рассчитать сумму себестоимости парсинга категории или всего сайта. В данном примере мы показали только парсинг категорий. Все показатели KPI, представленные в таблице – реальные для всех сайтов. Поэтому Вы можете прикинуть примерно, сколько будет стоить парсер того сайта, который вы у нас закажете.