В данной статье представим паттерн вероятностного поиска по сайту и дадим инструкцию по написанию кода. Дадим два алгоритма, написанных средствами языка PHP: поиск по папкам, а также поиск по базе данных SQL.

Оглавление
Исходные данные для вероятностного поиска.
Вероятностный поиск по файловой системе.
Клиентская часть
Пусть на сайте есть HTML-форма со строкой, куда нужно вбить фразу и кнопка “Найти”.
<form action = “/search.php” method = “post”>
<input type = “text” name = “search” placeholder = “Поиск по фразе” required>
<input type = “submit” name = “activated” value = “Найти”>
</form>
Откуда: тег <form> - тег формы ввода данных; атрибут action – ссылка на php-файл search.php, method = “post” – метод передачи данных по нажатию кнопки; <input> - тег ввода данных; атрибут name – имя глобальной переменной PHP; placeholder – подсказка в поле ввода; required – поле обязательно для заполнения; type - тип поля (text – текст и submit - кнопка); value – значение кнопки.
В текстовом поле в файл search.php передается значение текстового поля – переменная search, а также значение кнопки activated = true.
Серверная часть
Создаем файл search.php в корне сайта и прописываем там следующую конструкцию.
<?
if($_POST[‘activated’] == true) {
//алгоритм поиска
}
$_POST[‘activated’] = false;
?>
Переменная кнопки name = “activated” передается на обработку в виде булевы true или false. Если кнопка нажата, то срабатывает код внутри оператора IF. По умолчанию считается, что у переменной activated стоит значение false – то есть кнопка не активирована. Последняя строчка в коде выключает кнопку в целях безопасности.
Исходные данные для вероятностного поиска.
Весь остальной код мы будем прописывать внутри оператора IF под комментарием //алгоритм поиска. Первое что нужно сделать – просчитать введенной пользователем строке количество символов.
$string_array = str_split($_POST[‘search’]);
$sring_count = count(string_massiv);{
Откуда: $_POST[‘search’] – в этой переменной живет фраза, вбитая пользователем через HTML-форму на сайте; команда str_split разбивает эту фразу на символы и записывает в массив данных; команда count – рассчитывает количество элементов в массиве.
Далее по формуле можно рассчитать коэффициенты вероятности неточного вхождения подстроки в строку или файл.
Vk = 1/2k * log2 2k
Откуда Vk – вероятность неточного вхождения подстроки по отношению ко всему объему текста в строке или в файле (0 ≤ Vk ≤ 1); k = 0, 1, 2, …, N – коэффициенты разброса вхождений подстроки в строку или в целый файл.
Затем рассчитаем вероятность точного вхождения.
Dk = 1 - Vk
Рекомендуется, чтобы был Vk ≥ 0.05 и Vk ≤ 1. При Dk = 1 поиск становится более точный, при этом охват меньше и вероятность найти то, что действительно нужно – снижается.
Поиск нужного файла или строки осуществляется в цикле по формуле ниже.
Sk = Dk * C → floor(Sk)
C = const
Откуда Sk – циклический вероятностный поиск; С – количество символов текста в исходной строке, введенной пользователем на сайте. Сведем в таблицу найденные значения по этим формулам.
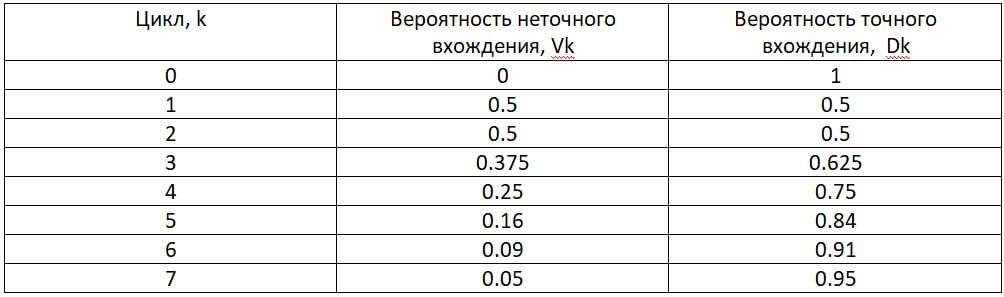
Здесь действует такое правило: чем выше вероятность неточного вхождения подстроки в файл или строку, тем выше охват поисковой базы и выше вероятность найти, то, что ищем.
Возьмем в пример фразу: парсинг базы данных. Количество символов будет равно 19 (C = 19) включая пробелы. При вероятности V5 = 0.16 охват поисковой базы будет равен D5 = 0.84. Рассчитаем количество символов подстроки.
S5 = 0.84 * 19 = 15.96 → floor(15.96) = 15
Берем минимальное целое значение, округляя php-функцией floor. Поиск по базе будет осуществляться по подстроке: "парсинг базы да". Затирается окончание “нных” и охват поиска становится шире в отличие от того случая, если бы мы искали целую подстроку при V0 = 0 и D0 = 1.
S0 = 1 * 19 = 19 → floor(19) = 19
Переходим от рассчетов к делу и в массиве данных запишем значения всех вычисленных вероятностей по Dk
$koef = array(0, 0.5, 0.375, 0.25, 0.16, 0.09, 0.05);
Вычислим параметр Sk в цикле for и сведем полученные значения к минимальным целым числам в массив $kf.
$kf = array();
for($k = 0; $k < count($koef); ++$k) {
$kf[$k] = floor((1 - $koef[$k]) * $string_count);
}
Далее соберем массив из подстрок.
$podstring = array();
$j = 0;
for($i = 0; $i < count($kf); ++$i) {
for($w = 0; $w <= $kf[$i]; ++$w) {
$podstring[$j] .= $string_array[$w];
}
++$j;
}
Когда все данные получены, то можно выполнить один из двух вариантов вероятностного поиска: по файловой системе или базе SQL.
Вероятностный поиск по файловой системе.
Первый способ заключается по поиску в файлах через команду file_get_contents. Сначала нужно получить доступ к каталогу (папке), где лежат файлы. Пусть это будет каталог: /catalog/dir/.
$catalog = scandir(‘catalog/dir/’);
Обойти в цикле for все файлы, в ней лежащие и просканировать каждый файл на подстроку, лежащей в каждом элементе массива $podstring. Обязательно нужно привести как строку поиска, так и все строки, находящиеся в файлах к нижнему регистру через команду strtolower.
for($q = 2; $q < count($catalog); ++$q) {
for($e = 0; $e < count($podstring); ++$e) {
if(
strstr(
strtolower(file_get_contents(‘catalog/dir/’.$catalog[$q])) ,
strtolower($podstring[$e])
)
) {
echo ‘Найдено: <a href = “catalog/dir/’.$catalog[$q].’”>тут</a><br>’;
}
}
}
В результате выполнения такого кода, на экран будут выведены все ссылки, соответствующие исходной поисковой фразе, введенной пользователем сайта через форму HTML.
Вероятностный поиск по базе SQL.
Прежде чем начать выкачивать данные с таблицы SQL, рекомендуется подключиться к базе данных. Для этого нужно ввести имя хоста, логин, пароль и название базы.
$auto = mysqli_connect(‘host’, ‘user’, ‘password’, ‘mybaza’);
Затем проверить, нет ли ошибки при подключении.
if(!$auto) {
die('<p style="color:red">'.mysqli_connect_errno().' - '.mysqli_connect_error().'</p>');
}
Извлеките таблицу SQL-запросом SELECT * FROM ‘tablename’ WHERE 1 средствами языка PHP.
$sql = mysqli_query($auto, "SELECT * FROM `tablename` WHERE 1");
Создайте массив и забейте туда всю таблицу построчно, выбирая из таблицы только те строки, куда входят подстроки из массива $podstring.
$array_table = array();
$key = 0;
while($row = mysqli_fetch_array($sql)) {
$imrow = implode(‘|’, $row);
for($u = 0; $u < count($podstring); ++$u) {
if(strstr($imrow, $podstring[$u])) {
$array_table[$key] = $imrow;
}
}
++$key;
}
На экран остается вывести все найденные строки из таблицы SQL и закрыть соединение с базой.
echo implode(‘<br>’, $array_table);
@mysql_close($auto);
Резюме.
В статье было приведено два алгоритма вероятностного поиска по фразе. Один по файловой системе сайта, другой – по таблице SQL. Для начала поиска вам необходимы исходные данные: подсчет количества символов по вероятностным коэффициентам. Затем сформированный массив из подстрок.
Когда все данные собраны, вы можете воспользоваться одним из двух вышеприведенных алгоритмов в зависимости от ситуации.
Наши услуги.
На нашем сайте Мы предоставляем услуги парсинга интернет-магазинов по низким ценам и собираем данные в базу excel.
Многие интернет-магазины используют платформу 1С-Битрикс для создания карточек товаров. Мы в курсе, что 1С-предприятие 8.3 имеет в своем арсенале модуль интеграции данных с сайтом. В этой программе можно через excel не только создавать карточки товаров, но и выгружать их на сайт. За раз можно весь ассортимент конкурента загрузить вместе с ценами, картинками и характеристиками.
Вы предоставляете нам сайт, который хотите спарсить. Мы оцениваем его на возможность обойти парсером. Если на нем стоит защита или данные выгружаются через JavaScript (JSON, AJAX), то обойти такой сайт мы не сможем.
Не путайте парсинг с API – мы этим не занимаемся. API – это постоянный обход сайта по двухсторонней договоренности и перекачивание фидов с одной базы данных на другую. Парсинг – разовый обход без договоренности. Не устанавливаем парсер на сайты – от этого ложатся сервера.
Стоимость будет завесить от сложности задачи. Она не превышает той суммы, которая установлена на главной странице нашего сайта.